A Glimpse into Swift Generic Meta-Programming
Make VFL Reborn in Swift with Compile-Time Safety
Preface
What is the most critical thing swings your decision when you choose a programming language?
Some people may say, the less lines of code they write, the better the language itself is. (Nope, the best programming language is PHP.)
OK. It might be true. But writing less code is not an essential indicator that truely leads a programmer to write less code. There is a better way where to inspect what primitives a programming language has.
There are some old-school programming languages which may not have multi-dimensional array. This leads an array cannot hold another one in itself and disallows developers to invent some recursive data structures and limits the expressiveness of the language. The expressiveness of a programming language, formally, is the computational capability of a programming language.
But the array example I mentioned above is just about runtime computational capability. What about the compile-time's?
For languages like C++, they have an explicit compile process and a "code template" infrastructures to do some compile-time computations by collecting the pieces of the source code and then organizing them into a piece of new code. You may have heard a buzz word: "meta-programming". Yes, this just is meta-programming (but at compile-time) and there is a bunch of programming languages includes C and Swift can do compile-time meta-programming.
Meta-programming in C++ relies on templates. In Swift, it relies on generics.
Though you can do compile-time meta-programming in these three programming languages, the capability of them are different. Since there are a lot of posts on the Internet that talked about the reason why C++ template is turing complete (a measurement of computational capability, you can just briefly treat it as "be able to compute anything that a normal computer is able to compute"), I don't want to waste my time on explaining it again here. What I'm going to talk about is Swift generics which also can do meta-programming at compile-time but owns a compile-time computability of push-down automata. You can briefly treat is as "is able to compute things with finite or recursive patterns."
Case Study : VFL Compile-Time Safety
There are a lot of Auto Layout helper libraries: Cartography, Mansory, SnapKit... But, are they really good? What if there were a Swift versioned VFL which ensures the correctness at compile-time and can collaborate with Xcode's code completion?
Truth be told, I'm a fan of VFL. You can lay many views out by using one line of code with intuitive symbols. With Cartography or SnapKit, things always go tedious.
Since the original VFL has some issues with modern iOS design, which cannot cooperate with layout guides, you may also want layout guide support in this set of API that we are going to implement.
Finally, in my production code, I built the following API which ensures compile-time safety and supports layout guide.
swift
Just imagine that how many lines of code you need for building equivalent things with Cartography or SnapKit? Cannot wait to know how I build it? Let's go for it.
Transforming the Grammar
If we dump the original VFL grammar into Swift source code by trimming the
string literal quotes, then it will soon be found that some characters
used by the original VFL such as [, ], @, ( and ) is not allowed
in operator overloading in Swift source code. Thus I transformed the
original VFL grammar into the following grammar:
swift
Figuring Out the Implementations
How to achieve this design?
An intuitive answer is to use operator overload.
Yes. I've done this with operator overload in my production code. But how does the operator overloading work here? I mean, why the operator overloading is able to convey our design?
Before answering the question above, let's check out some examples.
swift
The code above is an illegal input shall not be accepted. The relative original VFL is below:
Objective-C
We can find that there is missing view object or a -| after 4.
The system is expected to be able to handle correct inputs by making the compiler to accept it and also to handle incorrect inputs by making the compiler to reject it (because this is what compile-time safety means). The secrete behind this is not some black magic which applied by an mystic engineer whom has got a very high level title, but simply to make the compiler accept user inputs by matching user inputs with a defined function and to reject user inputs by mismatching user input with all defined functions.
For example, like the view1 - view2 in a part of the example above, we
can design the following function to handle it:
swift
If we take the UIView and BinarySyntax in the code block above as two
states, then we can read the code above as "a UIView transitions into
BinarySyntax when there is another UIView input with overloaded operator
-. Such a simple state transition is trivial. But it is the basic building
block of the system.
Naïve State Transitioning
The state transition with types and overloaded operator example I shown above may give you an intuition: we can build the system by enumerating all possible state transitions!
But... How many types we are gonna create with this solution?
What you may not know is that: VFL is expressible by a DFA, whose computability is a subset of push-down automata -- This is critical. Since we cannot build a system upon an weaker underlying system.
Yes. Since recursive texts like [, ], ( and ) are not really
recursive in VFL (only one level of them can appear in a correct VFL
input and cannot be nested), a DFA is able to express the complete
possible input set of VFL.
Thus I created a DFA to simulate the state transitions of our design. Watch out! I didn't take layout guide into consideration in this figure. Introducing layout guide may make the DFA much more complicated.
To know more about recursiveness and DFA with a plain and brief introduction, you can check out this book: Understanding Computation: From Simple Machines to Impossible Programs

In the diagram above,
|premeans prefix|operator and respectively|postmeans postfix|operator, double circle means an accepting state and single circle means a receiving state.
Counting the types we are gonna create is a complex task. Since there are
binary operators | and -, and there are unary operators |-, -|,
|prefix and |postfix, the counting method varies over these two kinds
of operators:
A binary operator consumes two input states but an unary operator consumes one. Each operator creates a new type.
Since even the counting method itself is too complex, I would rather to explore another approach...
State Transitioning with Multiple States
I drew the DFA diagram above by deadly putting possible characters to test whether a state receives them or not, this maps all the things into one dimension. May be we can create a cleaner expression by abstract the problem in multiple dimensions.
Before the beginning of further exploration, we have to acquire some basic knowledge about Swift operator's associativity.
The associativity of an operator (strictly speaking, of a binary operator, which means an operator connects a left-hand-side operand and right-hand-side operand, just like
-) is for which side of an operator, a compiler may prefer to use it as a parent node for constructing descendant sub syntax tree. The default associativity of Swift operator is left, which means the compiler prefer to use the left-hand-side of an operator to construct a syntax tree. Thus we can know for a syntax tree of a left associative operator, it is visually left-leaning.
Firstly, let's write down some simplest syntaxes:
swift
The syntax tree of them are below:
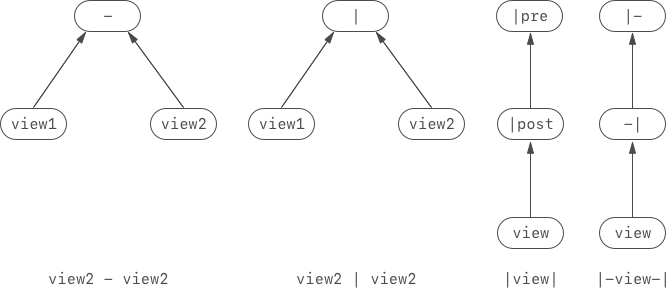
Then we can split the case into two:
Binary syntaxes like
view1 - view2,view1 | view2.Unary syntaxes like
|view1,view1-|.
This makes us to intuitively create two types:
swift
But is this enough?
Syntax Attribute
Soon it will be found that we can plug anything on the Lhs or Rhs of a
Binary, or the Operand of a Unary. To make the compiler really can
reject inccorect user inputs. We have to do some limitations.
Typically, inputs like |-, -|, |prefix, |postfix shall only be
appeared the at head and tail side of the syntax. We also want to support
layout guide (such as safeAreaLayoutGuide), which also should only be
appeared at the head and tail side of the syntax. Thus we have to constrain
these stuffs to ensured that they are only at the head and tail side of the
syntax.
swift
Moreover, inputs like 4, >=40 shall only be appeared when paired with
preceding and succeeding view/superview or layout guide.
swift
The above study of the syntax hinted us to split all things in the syntax
into three groups: layout'ed object (views), confinement (layout
guides and things wrapped by |-, -|, |prefix and |postfix), and
constant.
Now we are going to change our design into:
swift
Then for specific combinations of syntaxes like view1 - 4 - view2, we
can make the following syntax types.
swift
By conforming to the protocol Operand, a type indeed have got two
compile-time storage whose names are HeadAttribute and TailAttribute,
and values are of type of SyntaxAttribute. By calling the
function - (anyone in the above code block), the compiler checks if the
left-hand-side and right-hand-side matches any function with the name -
by reading generic constraints of the result
type (ConstantToLayoutableSpacedSyntax or
LayoutableToConstantSpacedSyntax). If it succeeded, we can say that: the
state has successfully transitioned to another.
We can see that, since we've set HeadAttribute = Lhs.HeadAttribute and
TailAttribute = Lhs.TailAttribute in the body of the types above, the
head and tail attribute of Lhs and Rhs is transferred from Lhs and
Rhs to the newly synthesized type now. The value is stored in the type
HeadAttribute and TailAttribute.
Then we've got our functions which make the compiler to receive input like
view1 - 4 - view2, view1 - 10 - view2 - 19... Wait! view1 - 10 - view2 - 19???
view1 - 10 - view2 - 19 shall be an illegal input which may be rejected
by the compiler!
Syntax Boundaries
Actually, what we did above just have ensured that a view is consecutive to a number and a number is consecutive is a view, it has nothing to do with whether the syntax shall be beginning with a view (or layout guide) and end with a view (or layout guide).
To make a syntax always begins or ends with a view, layout guide or anything
like |-, -|, |prefix and |postfix, we have to build a logic to
help our types to "filter" those invalid input out, just like what we
did like Lhs.TailAttribute == SyntaxAttributeLayoutedObject and
Rhs.HeadAttribute == SyntaxAttributeConstant above. We can find that
there are actually two groups of syntax mentioned in this kind of syntax:
confinement and layout'ed object. To make a syntax always begins
or ends with syntax in this two groups, we have to use compile-time or
logic to implemented it. Write it down in runtime code, it is:
swift
But this logic cannot be simply implemented with Swift compile-time
computation because that the only logic of Swift compile-time computation is
the and logic. Since we can only use and logic in type constraints in
Swift (by using the , symbol between
Lhs.TailAttribute == SyntaxAttributeLayoutedObject and
Rhs.HeadAttribute == SyntaxAttributeConstant in the example above), we can
only merge
(lhs.tailAttribute == .isLayoutedObject || lhs.tailAttribute == .isConfinment)
and
(rhs.headAttribute == .isLayoutedObject || rhs.headAttribute == .isConfinment)
in the above code block into one compile-time storage value then use the
and logic to concatenate them.
In fact, the
==inLhs.TailAttribute == SyntaxAttributeLayoutedObjectorRhs.HeadAttribute == SyntaxAttributeConstantis equivalent to the==operator in many programming languages. Moreover, there is a>=equivalent operator in Swift's compile-time computation which is:.Considering the following code:
swiftNow we can compose a generic specialization like
GreaterThanOrEqualToTwo<Three>which to make Swift compiler accept this specialization. Also we can compose another generic specialization likeGreaterThanOrEqualToTwo<One>to make the compiler reject the specialization.
Then we can change our design into:
swift
This time, we added two new compile-time storagies: HeadBoundary and
TailBoundary, and their values are of type of SyntaxBoundary. For view
or layout guide objects, they offer head and tail two boundaries of
SyntaxBoundaryIsLayoutedObjectOrConfinment. When calling the -
function, the a view or layout guide's boundary info transferred to the
newly synthesized type.
swift
Now, we just have to modify the signature of withVFL series functions into:
swift
Then, only syntaxes whose boundaries are of layout guide or views can be accept.
Syntax Associativity
But the concept of syntax boundaries still cannot help stop the compiler
from accepting inputs like view1-| | view2 or view2-| - view2. This is
because that even the boundaries of a syntax is ensured, you cannot
ensure the inner part of the syntax is associable.
Thus we introduce the third pair of associatedtype in our design:
swift
For syntax like |-, -| or layout guide in a syntax, we can just
disable their associativity in new type's synthesize progress.
It this enough?
Yes. Actually, I'm cheating here. You may wonder that why I can quickly spot issues by enumerating some examples and say yes to the question above without any hesitation. The reason is that I've already enumerated all the syntax tree constructions on paper. Planning on paper is a good habit for making things prepared.
Now the core concept of the syntax tree's design is very close to my production code. You can check it out at here.
Generating NSLayoutConstraint Instances
OK. Come back. We still have something to implement, which is critical to our whole work -- generate layout constraints.
Since the actual thing we get in the argument of withVFL(V:) function
series is a syntax tree, we can simply build an environment to evaluate
the syntax tree.
I'm trying to keep myself away from using buzz word, thus I was saying that "build an environment". But I cannot stop myself from telling you that we are going to build a virtual machine now.
By taking a look into a syntax tree, we can find that each level of the
syntax tree is whether an unary operator node, a binary operator node or
an operand node. We can abstract the computation of NSLayoutConstraint
into small pieces and ask these three kinds of node to populate the
small pieces.
Sounds good. But how to do the abstraction? And how to design those small pieces?
People who have experience on virtual machine or compiler constructions may know this is a problem related to "procedure abstraction" and "instruction set design". But I don't want to scare readers who may not have enough knowledge about virtual machine or compiler constructions, thus I call them "abstract the computation of
NSLayoutConstraint" and "small pieces" above.One more reason why I'm not talking with the term "procedure abstraction" and "instruction set design" is that: though "instruction set design" is the most eye-catching term, activities of "instruction set design" and activitities of "procedure abstraction" affects each other. Leaving these terms away from this post can help us understand the essence of the entire thing.
Abstracting NSLayoutConstraint's Initialization
Since we are gonna support layout guide, the old fashion API
swift
comes to be an unavailable option for us. You cannot get layout guide work with this API. Yes, I've tried.
Then we may come up with layout anchors.
Yes. This works. My production code makes use of layout anchors. But why layout anchors work?
In fact, by checking the documentations we can know that the base class
of layout anchors NSLayoutAnchor has a group of API that generates
NSLayoutConstraint instance. If we can get all the arguments of this
group of API in deterministic steps by evaluating syntax tree generated by
the "language" that we have just designed, then we can abstract a formal
model for this computation progress.
Can we get all the arguments of this group of API in deterministic steps?
The answer is "yes".
A Glimpse into Syntax Tree Evaluation
Before handing out the deterministic steps that compute arguments we need, we have to figure out how Swift syntax tree get evaluated.
In Swift, syntax trees are evaluated with the order of depth-first
traversal. The following figure is the traversal order of syntax
view1 - bunchOfViews in code block:
swift
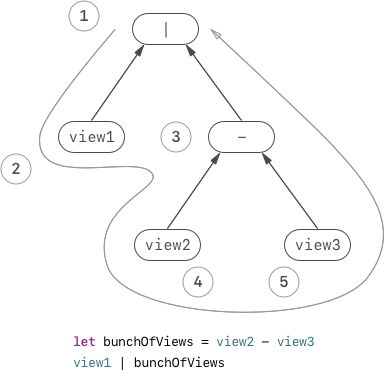
But even the root node is the first visited node in the whole evaluation
process, since it requires the evaluation result of its left-hand-side
child and right-hand-side child to complete the evaluation, it generates
NSLayoutConstraint instance at the last.
Abstract NSLayoutConstraint's Computation Procedure
By watching the figure of Swift syntax tree evaluation process above, we
can know that the node view1 was evaluated at the second but the
evaluation result would be used at the last, thus we need a data structure
to store each node's evaluation result. You probably would come up with
stack. Yes, I'm using stack in my production code. But I have to mention the
reason why we need a stack: with a stack, we are able to transform a
recursive structure into another recursive form or a degenerated form or an
aggragation of values. Since arguments of the API what we've just picked
above can be seen as an aggregation of values, thus stack is what we need.
You may have already guessed that I'm going to use stack, but intuition
doesn't work all the time. We may face problems rationally.
With stack, we have to put all the computational resource that is required
to initialize an NSLayoutConstraint instance in a single level.
Moreover, we have to keep the stack to memorize the head and tail node of the syntax tree that have been evaluated. Thus there should be a room for the head and tail node for each level of the stack.
Why? Take a look at the following syntax tree:
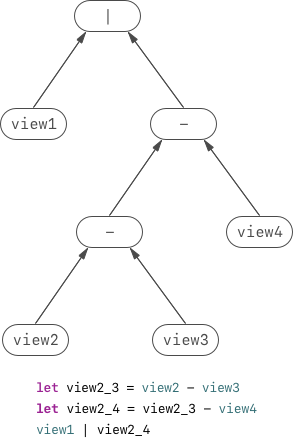
The syntax tree above was generated by the expression below:
swift
When we evaluating the node - at the second level of the tree (count
from the root), we have to pick view3, which is the "inner" node of the
tree, to make an NSLayoutConstraint instance. Actually, generating
NSLayoutConstraint instances always needs to pick the "inner" nodes
which with the perspective of the node being evaluated. But for the root
| node, the "inner" node soon comes to be view1 and view2. Thus we
have to make the stack to memorize the head and tail node of the syntax
tree that have been evaluated.
About the "Return Value"
Yes, we have to design a mechanism to let each node of the syntax tree to return the evaluation result.
I don't want to talk about how a real computer returns value over stack frames, because it varies over different size or abstraction patterns (since generics bring indirection -- which caused by the specialized type is unkown during the compile-time). In Swift world, because all things are safe, which means you cannot easily access the same piece of memory with different types unless by destroying the previous one and initializing another one, processing data with such a multiple pattern is not a good choice (at least for coding efficiency).
We just have to use a local variable in the evaluation context to keep the stack's last pop result (though we also can put it at stack's each level), then generate instructions to fetch data from that variable. Now we've done the design of the "return" mechanism.
Building the VM
The procedure abstraction that we have done shows a significant characteristic of stack, thus the "instruction set" can be designed as to manipulate a stack.
In fact, we just have to let the instructions to do following things:
Fetch views, layout guides, relations, constants and priorities.
Generate the information about which anchor to pick.
Make constraints.
Pop and push the stack.
The complete production code is here
Assessment
We've done the whole concept of our compile-time-ensured safe VFL.
The question now is what do we gain with it?
For Our VFL with Compile-Time Satefy
The advantage we got here is that a guaranteed of correctness of the syntax.
Syntaxes like withVFL(H: 4 - view) or withVFL(H: view - |- 4 - view)
would be rejected at compile time.
Then, we've got layout guide worked with our Swift implementation of VFL.
Third, since we're executing instructions which generated by the syntax
trees organized at compile time, the total computation complexity is
O(N), which N is the number of instructions a syntax generated. But
since the syntax trees are not constructed as compile-time, we have to
construct the syntax tree at runtime. The good news is that, in my
production code, the syntax tree's type is of struct, which means the
whole syntax tree is constructed on stack memory but not heap memory.
In fact, after a whole day of optimizations, the performance of my production code exceeded all the implementation of existing alternative solutions (includes Cartography and SnapKit), which of course includes the original VFL. I would place some optimization tips at the end of this post.
For VFL
Theoretically, the original VFL may have a bit more advantages on
performance over our design -- because the VFL strings can be fetched as C
strings, they are loaded directly and there are no initializations shall be
done before using them. After that, the UI framework of the targeted
platform is ready for parsing the VFL string. Since VFL's grammar is quite
simple, building a parser works with time complexity of O(N) is also quite
simple. But I don't know the reason why VFL is the slowest solution which
helps developers to build Auto Layout constraints.
Benchmark
The following result is measured by building 10k constraints on iPhone X.
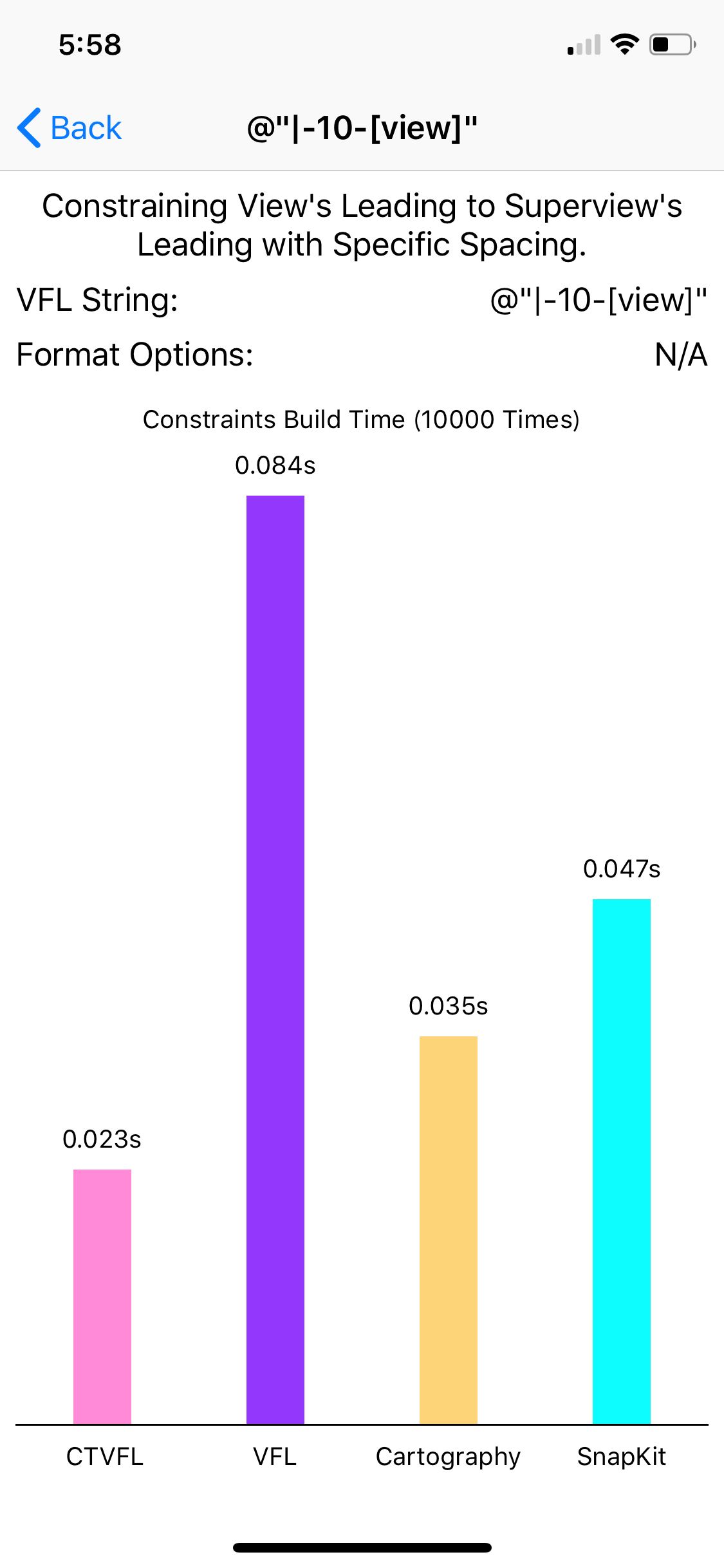
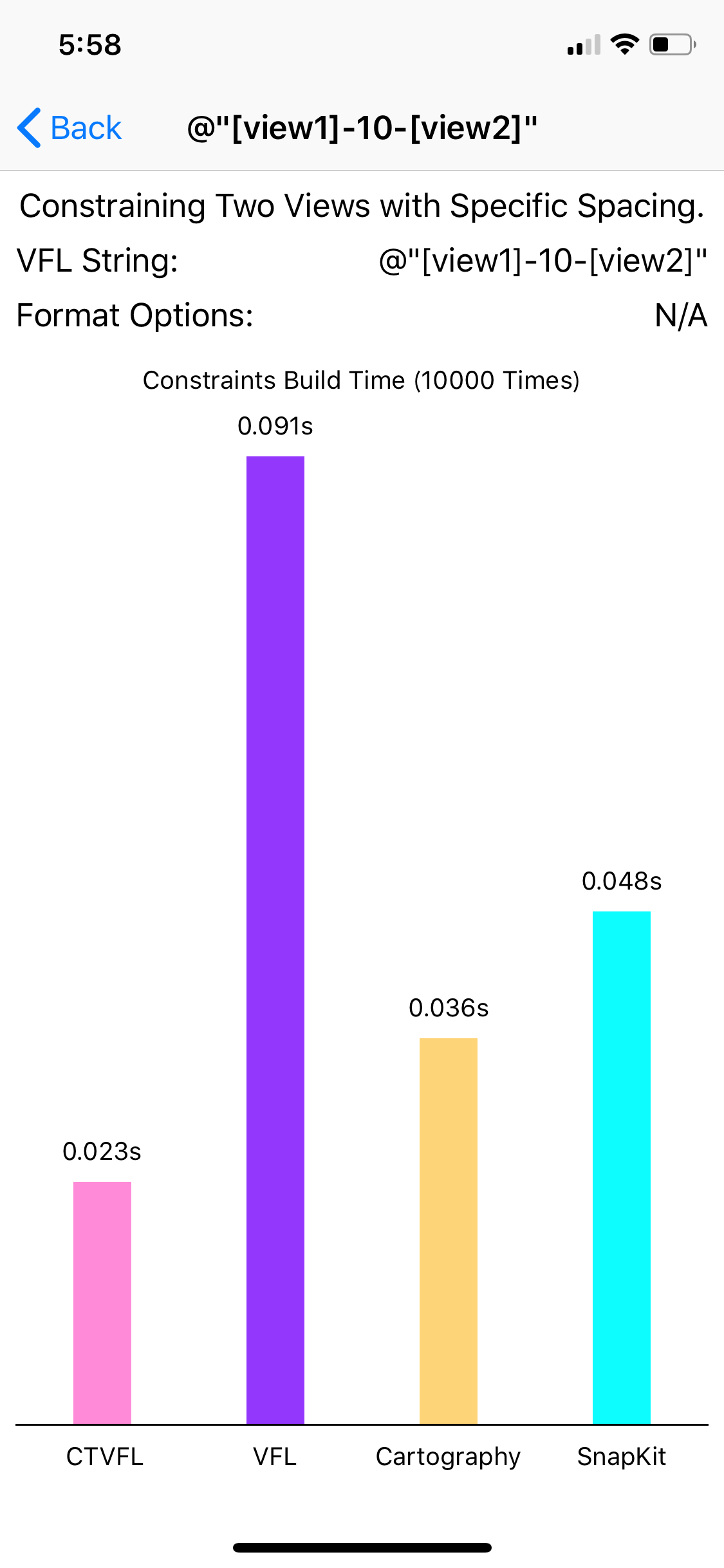
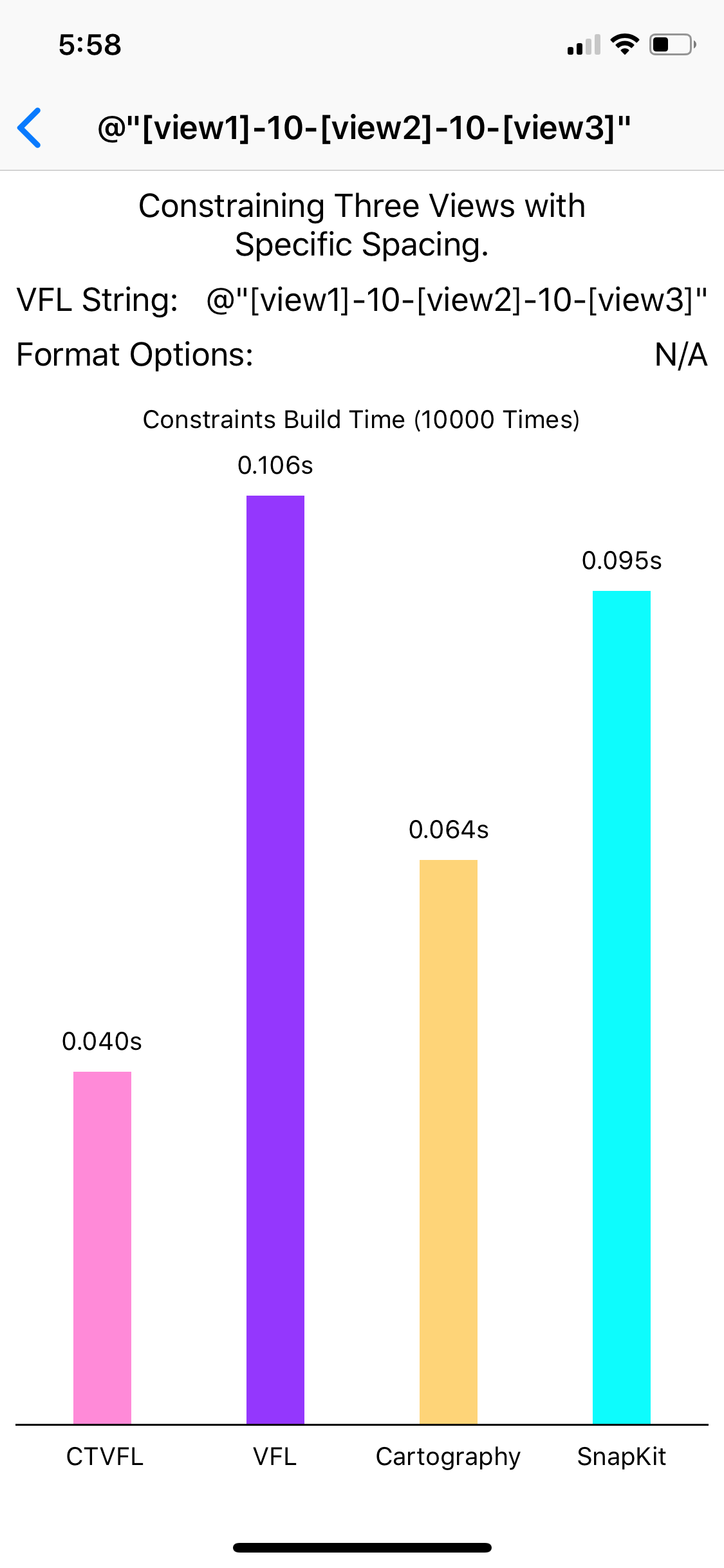
Thank for your reading of this long post. I have to apologize. I lied at the title. This post is totally not a "glimpse" into Swift generic meta-programming, it talks about many deep content about computational theories. But I think this post could give a lot of intuitive example for these theories.
Finally, may the generics meta-programming in Swift not come to be a part of contents in iOS engineer interview.
Revisited at 12nd Sep, 2022.