Build Your First 24/7 Agentic Loop
Fun fact: My Claude Code usage reached USD 3,000 in September, 2025.
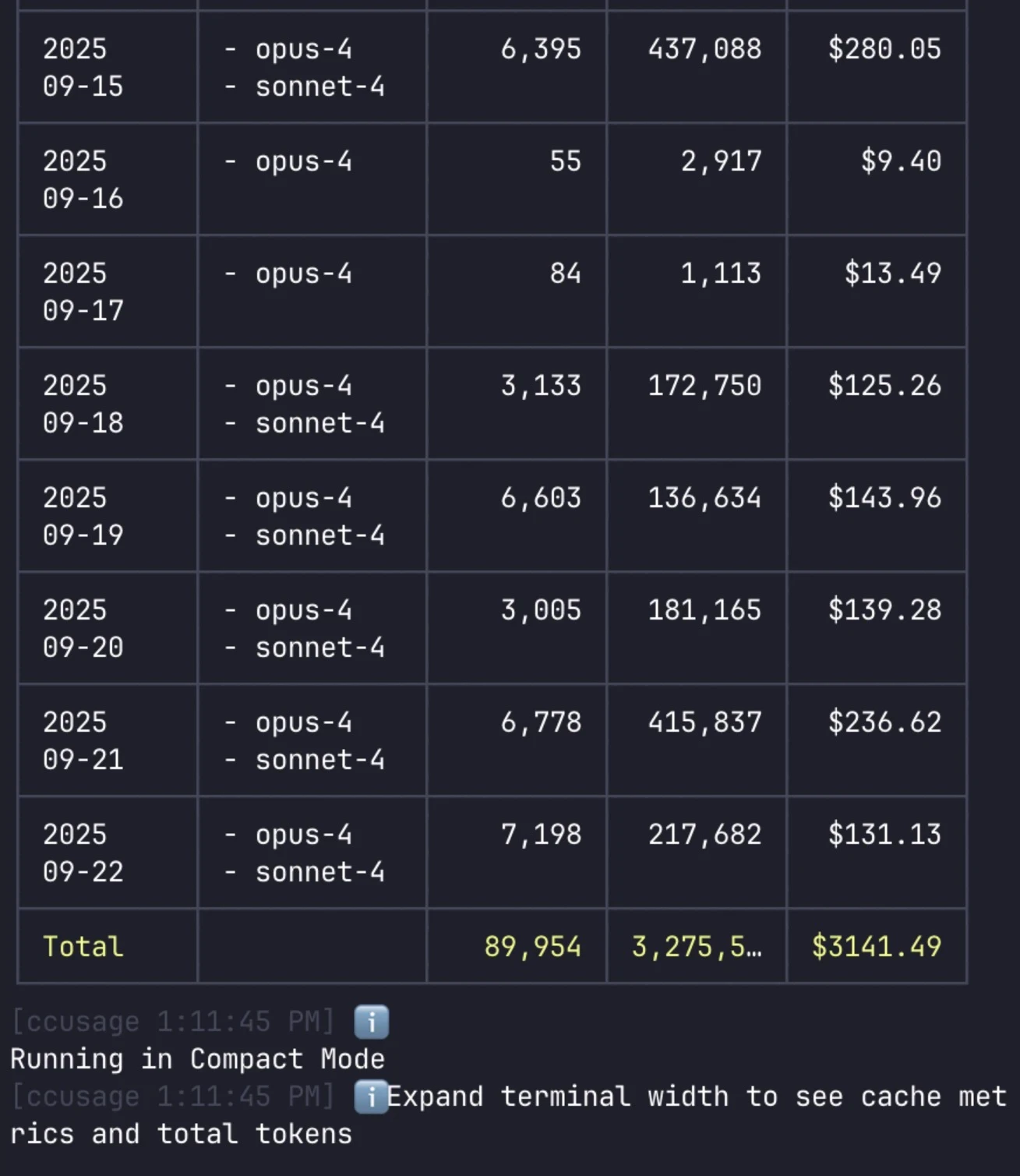
That's because I've been running Claude Code inside a 24/7 agentic loop to power my side project. While I sleep, the loop evaluates, spawns subagents, and keeps moving forward. When I wake up, progress is already made.
But the magic isn’t tied to Claude; once you grasp the essence of the configuration you can replicate it with models and agent runtimes that implement the same elements.
Here's how you can build your own.
The Secret Behind the Curtain
The truth is: the latest large-language models --- Claude 4, GPT-5 --- have been trained with agent tasks. They "know" how to evaluate, plan, call tools, and hand control back. You don't need a massive framework. You just need a contract and a loop.
The Essence of an Agentic Loop
To make “a contract and a loop” concrete, the diagram below shows the minimal flow: the evaluator chooses the next action, spawns executors to use tools, executors report results, and control returns to the evaluator until the goal is met.
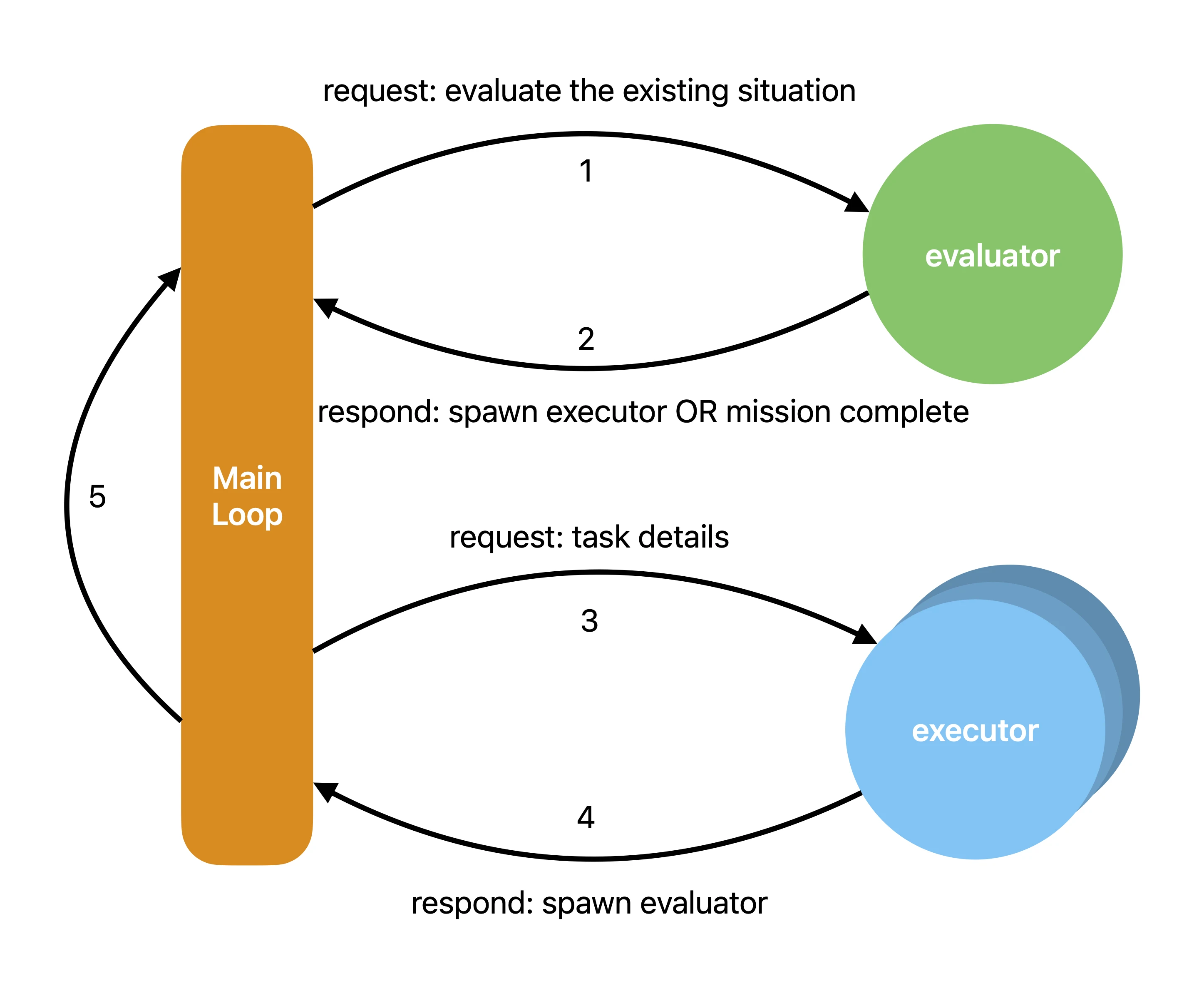
However, to turn that flow into a working system, three components must work together: the right model, prompts that enforce the contract, and an agent runtime designed for tool use:
Get the right model
Pick an advanced model that can:
- Follow strict JSON formats under prompt pressure.
- Stay disciplined about roles and actions.
- Reason sensibly about tool use without hallucination.
Write prompts with contracts in mind
The backbone of your loop is a fixed-format schema. Every evaluator and executors must respond in this structure. This turns free-form LLM chatter into predictable, machine-readable communication.
Support tools
Without tools, your loop is just self-talk. With CLI commands, it can run tests, fetch data, patch code, or monitor systems. Subagents aren’t even required, since you can spawn external agent instances to build the evaluator-executor heartbeat via the
bashtool.
Writing Your First Contract-Driven Prompts
You’ve seen the loop and its roles. Now we’ll wire real prompts using Claude Code subagents and a custom command to build a loop that cleans up TODOs and FIXMEs across your repository. No standalone schema files—the contract is exactly what your prompts already define. Claude 4 is a solid choice for running a 24/7 agentic loop.
Project URL: agentic-loop-palyground
1) The Structure of the Loop
The loop has three components:
cleanupcommandcleanup-evaluatorsubagentcleanup-executorsubagent
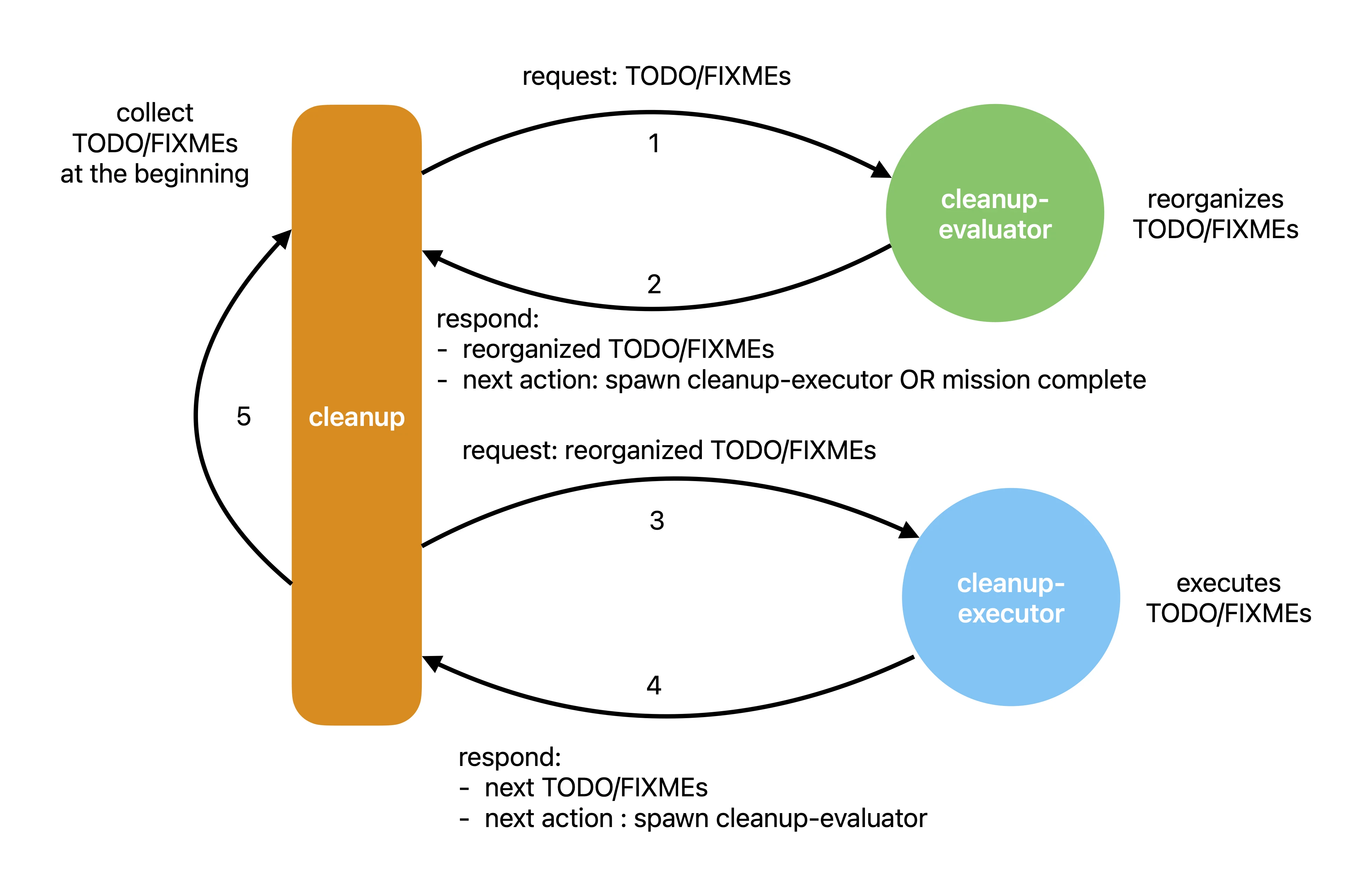
The cleanup command is the loop’s entry point and hosts
the main agent. It first scans the repository for TODO/FIXME items and
prepares a working list, then passes that list to the cleanup-evaluator
subagent.
The cleanup-evaluator subagent triages and orders the list, then
responds to the main agent with the reorganized list and a next action
of spawn(cleanup-executor).
The main agent then follows the response from the cleanup-evaluator,
spawning a cleanup-executor subagent and passing the reorganized list to it.
The cleanup-executor subagent dequeues the first TODO/FIXME item from
the reorganized list, executes it, updates the list when execution
completes, and responds to the main agent with the updated list and a
next action of spawn(cleanup-evaluator).
The main agent then follows the response from the cleanup-executor,
spawning a cleanup-evaluator subagent and passing the updated list to
it, thereby returning to the beginning of the loop.
2) The Contract
The key to this loop is ensuring the main agent and subagents always follow the contract. The good news: the contract is straightforward. In this example, each subagent receives a JSON object from the main agent in the following format:
json
and responds to the main agent in the following format:
json
3) Collecting TODOs/FIXMEs with Tool Call
You might be wondering what [incomplete_item_list] means. Think of these
as “variables” inside the prompt. They’re gathered through tool calls, triggered
by the prompt at the beginning of the cleanup command:
cleanup.mdmarkdown
However, the raw outputs of this command aren’t ready to use as-is. We need to guide the agent on the expected format and instruct it to reshape the results into a JSON object that follows the required schema.
cleanup.mdmarkdown
4) Enforcing the Contract with Prompts
The contract is baked into the prompts themselves—no hidden tricks, just clear imperatives and consistent repetition until the model obeys.
The snippet below shows the main agent spawning a cleanup-evaluator at the start of the loop.
cleanup.mdmarkdown
On the cleanup-evaluator side, we should also enforce the contract.
cleanup-evaluator.mdmarkdown
Once the cleanup-evaluator is ready to conclude its evaluation, it
prepares a response to the main agent using the contract format. In this
example, its next_action is always to spawn a cleanup-executor or tell
"mission complete".
cleanup-evaluator.mdmarkdown
Back in the main agent, it follows the response from
the cleanup-evaluator subagent, spawns a cleanup-executor subagent,
and passes the lists to it.
cleanup.mdmarkdown
At this point, the contract allows the main agent to spawn a
cleanup-executor subagent to execute the next TODO/FIXME item. However,
we still need to instruct the main agent to follow responses from
subagents other than the cleanup-evaluator:
cleanup.mdmarkdown
Finally, the main agent needs to know when to end the loop:
cleanup.mdmarkdown
Now we've built our first agentic loop with a collection of contract-driven prompts.
Have a Try
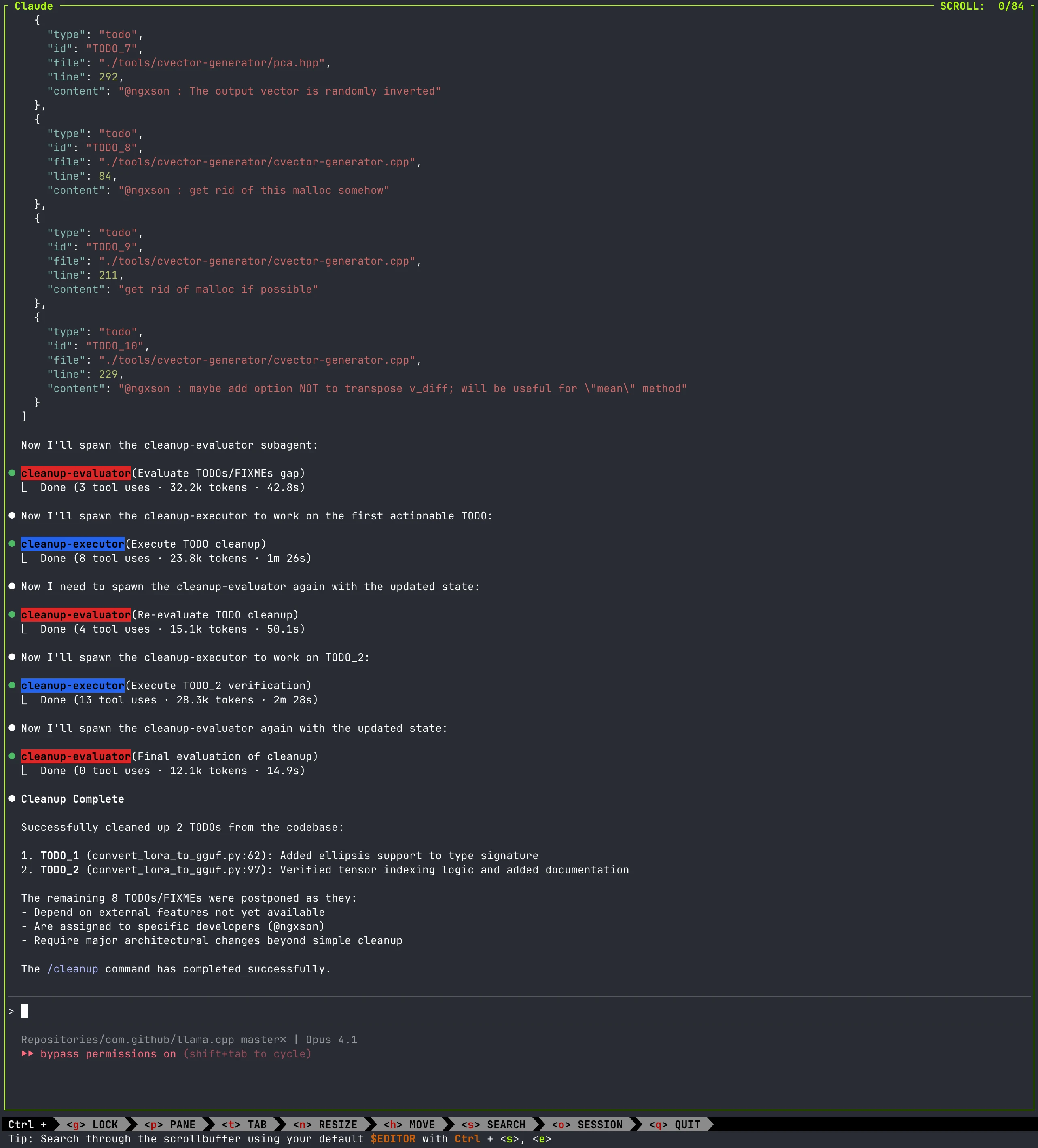
Here's what happens when you run this loop against the llama.cpp project. The loop processes exactly 10 TODOs and FIXMEs before completing—no ambitious mission required, just a focused cleanup cycle that demonstrates the core mechanics in action.
Running 24×7
Running a loop around the clock is about feedstock, not just uptime. A loop survives by continuously converting A into B: turning one kind of artifact into another on repeat. If A is an idea and B is a program (or a fix, a test, a release), then a 24×7 loop needs endless ideas.
We don’t actually have infinite ideas. The practical pattern is this: you design the loop to tackle work that’s substantial enough to buy you thinking time. While the agent is converting A→B — compiling, testing, packaging, or deploying — you use that breathing room to decide the next A. Optional feeders like TODO/FIXME scanners or issue trackers can surface candidates, but they don’t replace your judgment. The loop does meaningful work; you curate the input stream. That’s a perfectly valid way to run a 24×7 operation.
Beyond the Claude Code
At this point, you might ask: I'm not using Claude Code; I'm using Codex. What should I do? The answer is simple: the approach stays the same. This loop doesn't depend on any vendors; it rests on three essentials: a contract, a loop, and a runtime. Put simply, the evaluator chooses the next step, the worker carries it out, and the main agent routes and safeguards. Everything else is implementation detail.
Claude Code is convenient because it offers two helpful primitives:
- Subagents: lightweight agent instances with their own prompts and roles.
- Custom Commands: first-class command blocks that carry prompts and tool wiring.
But neither is mandatory. You can replace both:
- Replace Subagents with a tool call that starts another AI agent instance (for example, invoke a CLI that spins up a new agent and returns its structured response).
- Replace Custom Commands with a shell script that sends a custom prompt to launch an AI agent.
As long as you preserve the contract and the loop, the mechanics are
interchangeable. Your main agent routes, enforces the schema, and keeps
cycling until next_action is mission_complete.
Comparison with LangChain and LangGraph
However, you might be wondering: why not just use LangChain or LangGraph? The table below makes the trade-offs clearer.
Aspect | Agent runtime | LangChain or LangGraph |
|---|---|---|
Requirements | Appropriate model | SDK + tools + memory abstractions |
Setup | Prompts | Chains or graphs |
Tool calling | Via prompts | Via prompts and system-level adapters |
This comparison lays out the trade-offs between the agent runtime approach described here and frameworks like LangChain or LangGraph. It highlights three essentials: what you need to build a loop, how you set it up, and how tools are called.
From the table, it’s clear the agent runtime path is lighter to boot, leans on native tools so it fits any stack, stays vendor-neutral, and keeps humans in charge of the input stream—while the loop itself does meaningful work 24×7.
Conclusion
Building a 24×7 loop doesn't require LangChain or LangGraph. All you need is:
- A model trained with agent tasks.
- A prompt-enforced contract.
- A runtime that supports tool use.
With that, you can run Claude Code (or Codex) in a loop that works while you sleep.
Try it tonight. Tomorrow morning, you might wake up to progress already made.