How I got 1,300+ Downloads in 24 Hours
I am the author of the opencode-vision plugin. It lets you delegate visual tasks to a vision model from one of your existing AI subscriptions while using a text-only model, such as GLM-5.2 or DeepSeek V4, as the main model in OpenCode.
npmjs.com showed that this plugin hit 1,300+ downloads in the first 24 hours after the release. However, I also made a basic and costly mistake: my first Reddit post and X article did not mention the GitHub repository. People had no clear place to file issues or leave feedback. Even worse, another project already used the name opencode-vision, so search results could send users to the wrong place.
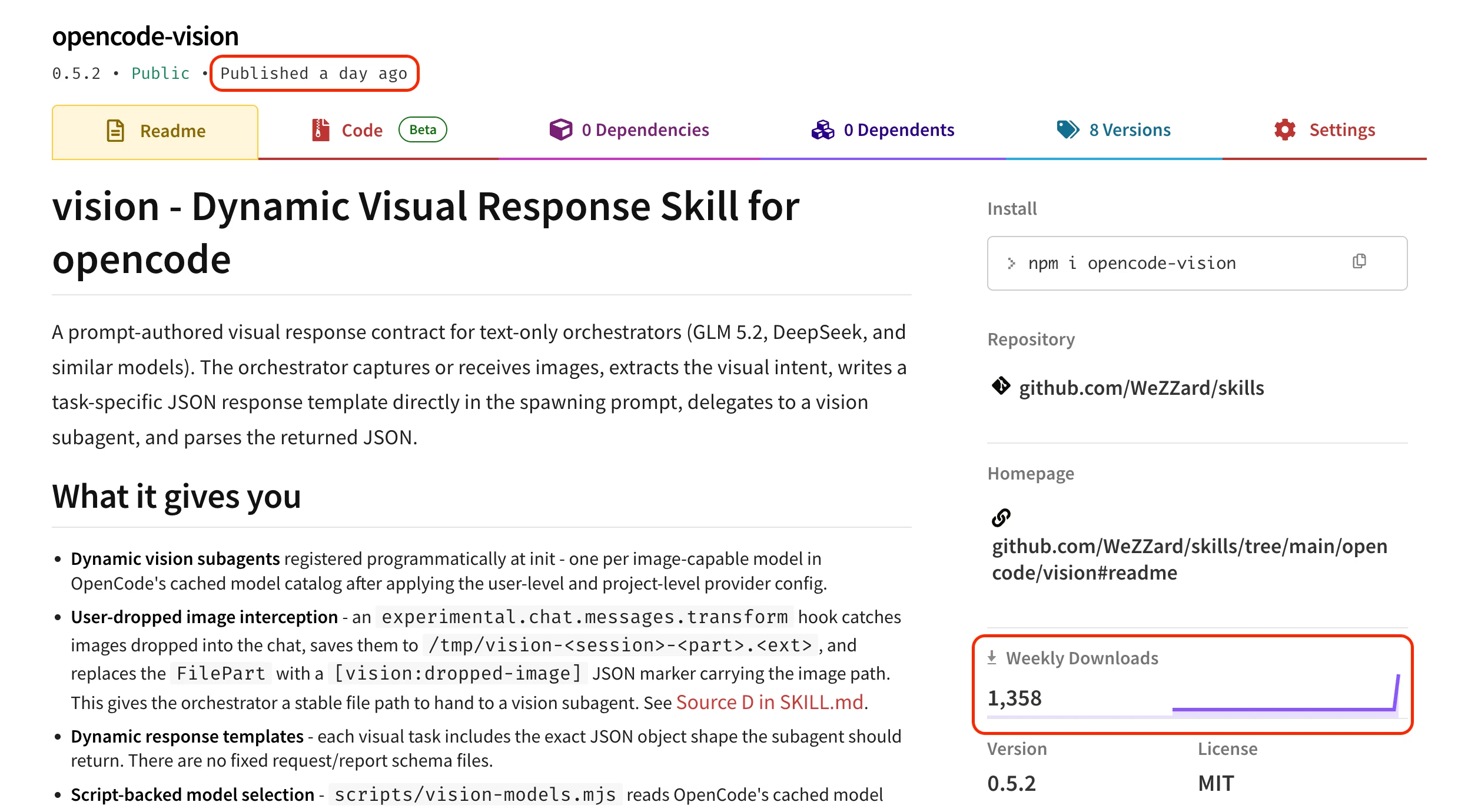
So let me fix that first: if you installed the plugin with opencode plugin opencode-vision -g, please file issues and feedback in the correct GitHub repository.
My background is industrial design. Design students rely on portfolios when they apply for schools and jobs. A good portfolio explains the key decisions a designer made at each pivotal moment in a project: what changed, why it changed, what effect it had, and what the designer learned. This post is that kind of portfolio. It records the decisions and takeaways behind this plugin's creation, go-to-market, and distribution.
I hope this post helps if you are building your own product and struggling with go-to-market or distribution.
What I Would Do Again
1. Go to Market Multiple Times
Origin of the Requirement:
After I ran out of Claude Code and Codex quota, I tried GLM-5.2 in OpenCode. From my perspective, GLM-5.2 felt close to GPT-5.5 xhigh in coding-agent work with Ollama Cloud's API set to max reasoning effort.
But its multimodal experience was broken in two places: (1) Users could not send images; (2) When GLM-5.2 used computer-use or browser-use tools to verify UI, it could only read the AX tree, the accessibility structure prepared for assistive technologies. It could not see pixels, so it could not perform reliable UI fidelity checks.
I first solved the problem for myself with a subagent backed by Kimi K2.7 Code. I just delegated visual tasks to this subagent. Then I wanted to turn this workflow into a plugin, because that would let me reuse it and run an Open Source model stack in OpenCode CI/CD: GLM-5.2, Kimi K2.7 Code, and DeepSeek V4.
Go-to-market the first time:
After GLM-5.2 launched, a Zhipu employee asked on X for the most wanted features. The replies were full of requests for vision support. That was a strong demand signal. I knew I was not alone.
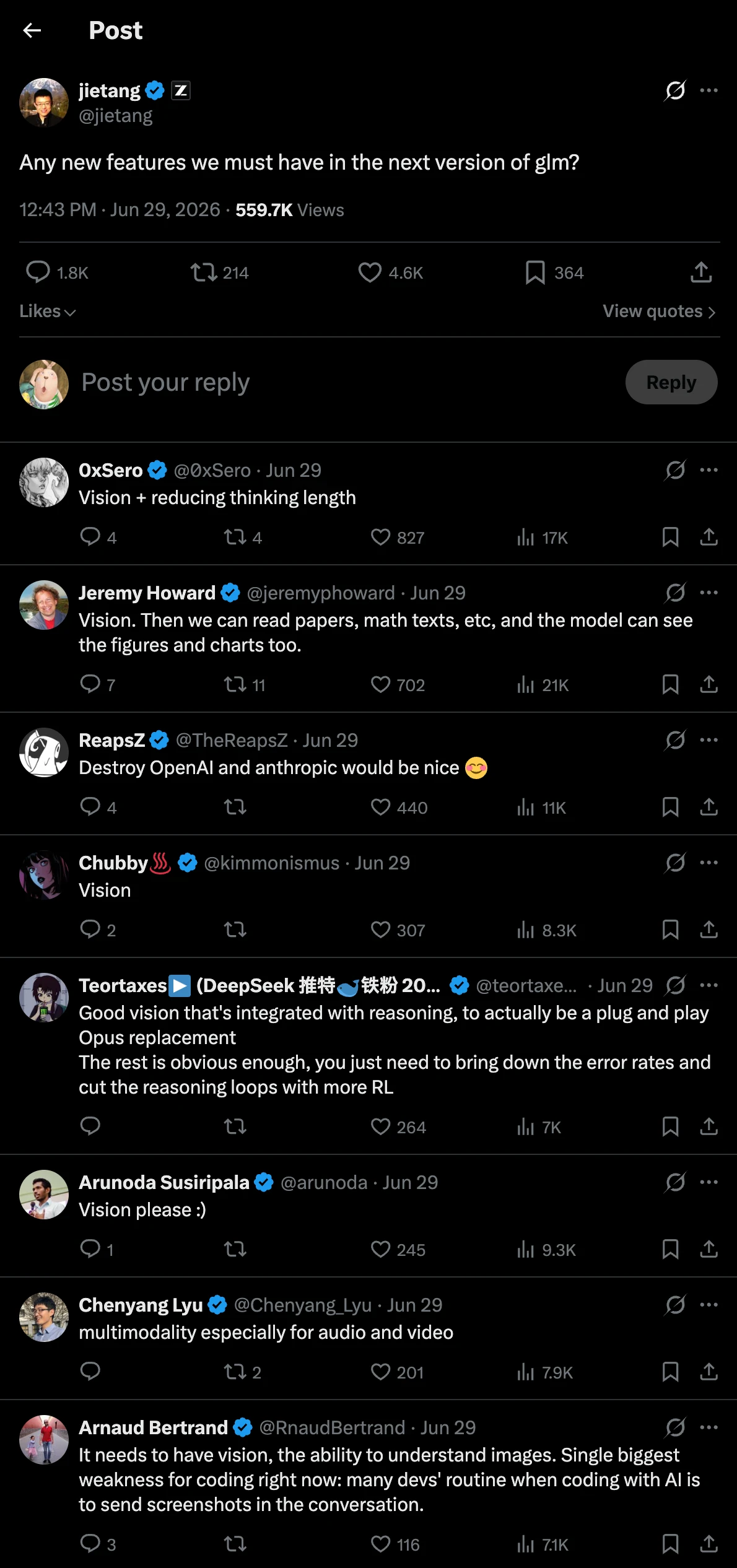
So I raised the priority of turning my workaround into a plugin. OpenCode plugins do not have a paid marketplace, but a useful plugin can still become a distribution asset and a trust asset in a developer community.
Go-to-market the second time:
Because I was building an OpenCode plugin, while Zhipu had also shipped ZCode, I had one more question: how many OpenCode users had the same pain?
While building the plugin, I posted a screenshot on X showing my own GLM-5.2 setup completing a visual task in OpenCode. People liked it. More than one person asked how it worked and whether I could share it.
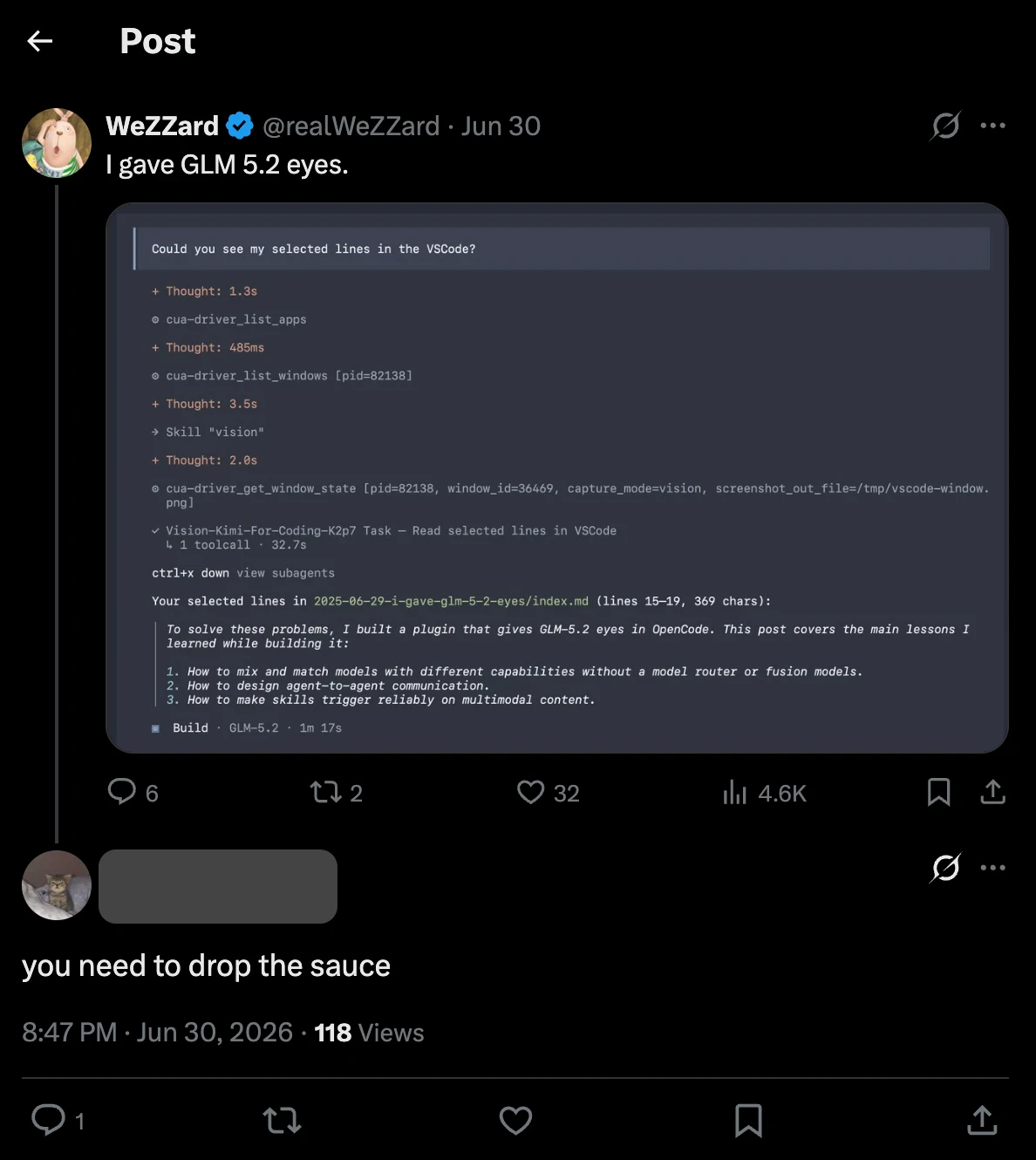
At that point, I knew that the vision gap in GLM-5.2 inside OpenCode was a common user pain, not only my private annoyance. I prioritized the plugin building.
2. Optimize the First-Success Path
I use path to first success to describe this sequence:
Desire -> Get -> First Use -> First Success
In other words:
- The user desires the product.
- The user gets the product.
- The user uses the product for the first time.
- The user succeeds with the product for the first time.
This path decides how many interested users actually reach the experience you designed. If that number is low, your feedback and word of mouth become distorted — and so do the negative signals you need most.
We see this problem all the time. Some physical products only ship to one country. Some digital products require a credit card from one country. We may want to try them, but the product experience never reaches us. That hurts revenue, distribution, and product iteration.
For opencode-vision, the "get the product" step had almost no friction:
shell
That command works well in Reddit posts, Discord messages, and articles. It also supports impulse trials.
But before a user can finish the first visual task, there are still several forks:
- How does the user provide a vision model?
- How does the user choose a vision model?
- How does the user trigger a visual task through that model?
If each fork becomes a dialog, the first-success path becomes a maze. Even worse, users may not know enough to answer those dialogs. For example: what is an API format, and what should the base URL be?
The final experience used three decisions:
- Find vision models from the providers already configured in OpenCode.
- Ask the user to choose one of those models on the first visual task.
- Shape the skill description to cover multimodal content from both user input and tool results.
That reduced first use to two dialogs:
- Choose a vision model from the user's own subscriptions.
- Allow OpenCode to pass image content to the visual-task subagent through a temporary folder.
Both are decisions users can make with confidence.
3. Do Not Chase Every Wave
24 hours after my plugin launched, Zhipu started promoting ZCode in the international community. ZCode has no vision routing when you use non-official plans. At the same time, international users often criticized the official plans as slow or rate-limited. Several developers I talked to had already chosen Ollama Cloud as their GLM-5.2 provider.
I thought the plugin might have a second life in ZCode, so I asked Codex to port opencode-vision into a ZCode plugin.
But testing changed my mind. Because of ZCode's design, the same implementation could not wake the visual-task skill. If you put image content into ZCode while the main model cannot handle multimodal input, ZCode stops with errors before the skill gets a chance to run, even though ZCode supports subagents.
To get the same behavior, I would need a fusion model: a model-like wrapper that combines multiple models and routes work by task type.
However, that's not my edge. The first version, which routes by modality, would be simple. I even had a name for it: OpenFusion. But opportunity cost matters. I decided I could use my strengths better elsewhere, so I stopped. If you like the name OpenFusion, feel free to use it for your own fusion-model product.
Mistakes I Will Not Repeat
1. I Missed the Timing Window
Judging by the attention shift after Fable 5 returned on July 1, 2026, the main distribution window for this plugin was only about 24 hours. GLM-5.2 launched on June 16, 2026, so I used only about one day out of a roughly two-week window. I did not strike while the iron was hot.
The root cause was simple: I noticed too late that GLM-5.2 was approaching GPT-5.5-level usefulness for my work. That means I lacked the right evaluations.
From my past experience, model capability jumps should be discovered through evaluations, and those evaluations should come from personal work and life. In other words: use AI like someone six months in the future.
Live with the bad cases. Extract them into evaluations. Automate those evaluations. When a new model launches, run them on day one, compare the results with other models, and you will know where the new model sits in the market.
2. I Did Not Design the Traffic Chain
My Reddit post and X article did not route people to the GitHub repository. That weakened the plugin's spread on GitHub.
I also did not start with a standalone GitHub repository. As a result, the new standalone repository had zero stars even after the npm download spike. I had kept the plugin inside a monorepo because, from 2025 through mid-2026, monorepos were a useful part of AI context engineering.
But standalone repositories work better across platforms. Search engines, GitHub, and social platforms recognize them more easily, which helps distribution. On the other hand, since Fable 5, good context engineering no longer has to depend on a monorepo. Do not force a monorepo just to get context-engineering benefits unless you are using older models such as Opus 4.8, GPT-5.5, and GLM-5.2.
The naming problem made this worse. Before my plugin, another project had already used the name opencode-vision. That project connects vision models through MCP and expects users to provide their own API settings and endpoints. Because the names collided, Google could prefer the older project.
Adding all this up, it caused two problems:
- I got over 1,300 downloads in 24 hours, but I did not convert that traffic into GitHub stars, issues, discussions, or future reach.
- Users who wanted to report problems could land in the wrong place.
Traffic that does not become an asset is a flash in the pan. The second problem is even worse for long-term product operations.
3. I Did Not Press the Advantage Soon Enough
I actually noticed the traffic-chain problem soon after posting. Then I checked npmjs.com, saw more than 800 downloads in five hours, and went to sleep.
I fixed the traffic chain only after the first 24 hours. At the time, I thought splitting the whole skills monorepo into a standalone repository would be annoying. In reality, if the goal was only to improve the traffic chain, I only needed to move opencode-vision out. With Cursor's help, I moved opencode-vision into its own repository, re-published it on npm, validated everything locally, and finished the whole thing in under half an hour.
Regrets
1. The Product Can't Teach Me Pricing
This plugin consumes the user's own AI subscriptions, and OpenCode has no paid plugin marketplace. That makes it a bad idea to turn the plugin into a direct-revenue product. It works better as a distribution asset and a trust asset.
But that also means it did not develop my ability to price a product and charge directly.
That ability matters, especially for people from mainland China. Many of us grew up with a line often translated as: "A gentleman understands righteousness; a petty person understands profit" (「君子喻于义、小人喻于利」). But real business does not work that way. In business, profit comes first.
2. The Product Cannot Support Online Evaluation Cleanly
Because opencode-vision is a plugin, online evaluation would be hard. Data collection would require another consent dialog, and that dialog would damage the "first-success path".
A normal AI product can reasonably ask users to send data to a server. A plugin that only delegates visual tasks has a harder case to make. Why should it send data to the plugin author's server? A data-collection dialog would likely stop many users before they ever reach the first successful visual task.
Key Takeaways
1. Build in Public
By 2026, build in public has become common advice. But why should we do it? Shouldn't normal business logic favor secrecy?
Yes and no.
In my case, the public part was simple: I posted screenshots on X showing GLM-5.2, as the main model in OpenCode, completing visual tasks. That post received likes and replies, and people in the community asked me to share the approach.
That action validated both the demand and the signal strength. The worst commercial mistake is fake demand: building something nobody uses. Large companies can hide fake demand inside internal empire building. A personal project should avoid it.
And I did not reveal the implementation, the experience design, or the best route until release.
This launch also taught me a larger lesson: build in public is not only demand validation. It also builds the distribution channel. I will write about that separately.
2. Use AI Like Someone Six Months in the Future
An AI-native product, person, or organization should gain a superlinear improvement when models improve. Otherwise, it is not AI-native.
To reach that point, you have to use AI like someone six months in the future. Six months from now, AI will touch more of our work and life. Start living in that future today. Notice the bad cases, turn them into evaluations, automate them, and rerun them when a new model arrives. That is how you detect a capability jump of a new model on day one.
But how? You must rebuild as much of your work and life around AI as possible. Except for work that truly requires your craft, AI should lead the work—not just help you do it.
3. Design Your Traffic Chain
When you publish online, design the traffic chain before you post.
- Across platforms: put the right content on the right platform, but always route people toward the place where you run core operations and collect feedback.
- Inside a platform: imagine a reader clicks your profile because one post interested them. Decide what they should see there that would make them follow you.
With that design, traffic can become a distribution asset or a trust asset. A hit on one platform can help another platform. A hit post can lift older posts, bring followers, and earn bookmarks.