当 Swift 编译器删除了标准库中的代码 - 记修复 Swift 6 中的冗余 Load 指令消除优化器
最新更新:苹果已接受该问题的修复。最终解决方案在相关代码所有者 review 后进行了调整。
蛇年春节假期前,一位同事向我展示了一个由 use-after-free(释放后使用)错误导致的神秘崩溃。最近,我有时间深入研究这个问题,并发现崩溃是由 Swift 编译器的错误编译引起的。下面是最小复现代码,必须使用 -Osize 优化级别编译。我们可以通过在编译过程中启用地址检查器(address sanitizer)来检测 use-after-free 问题。
swift
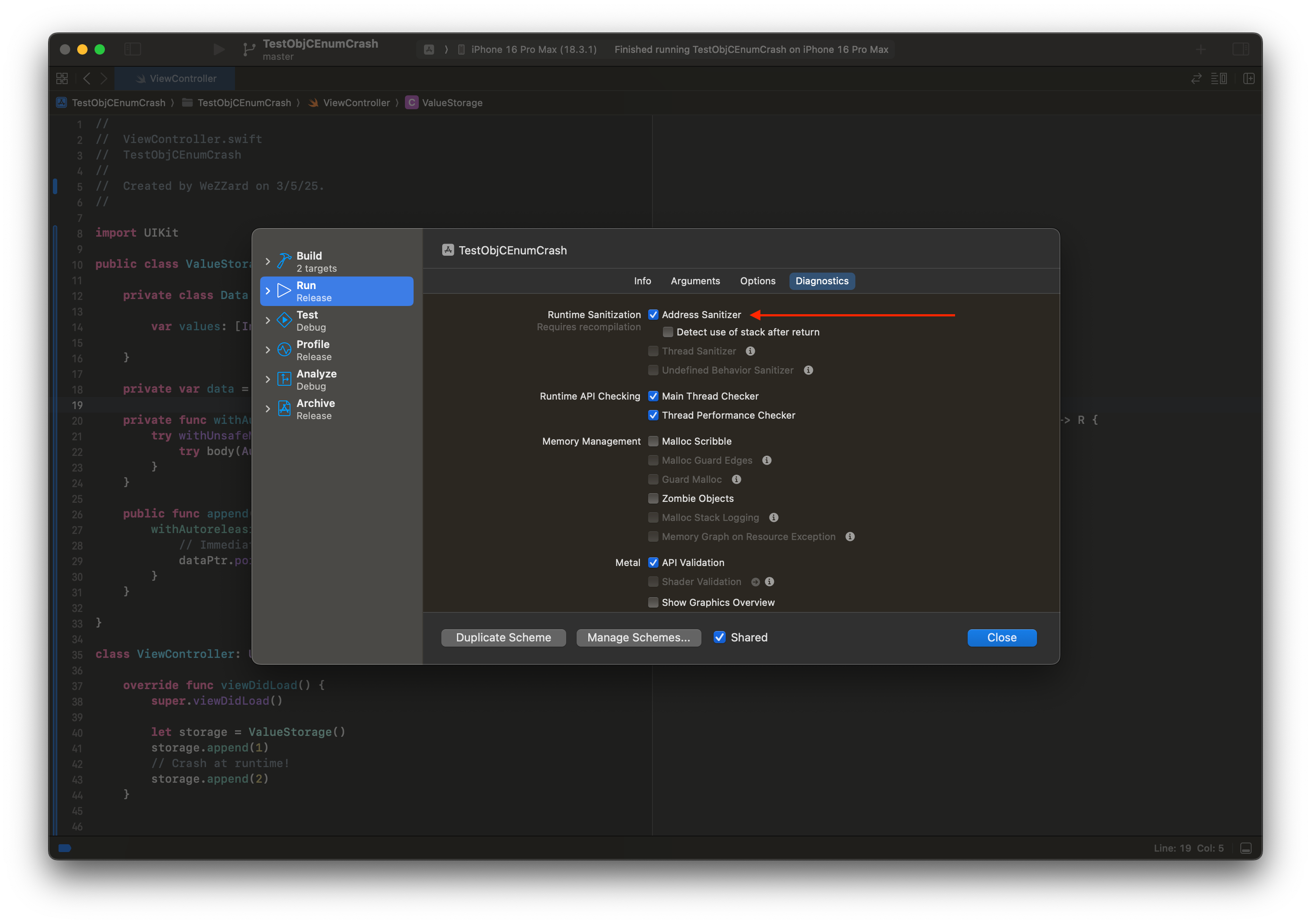
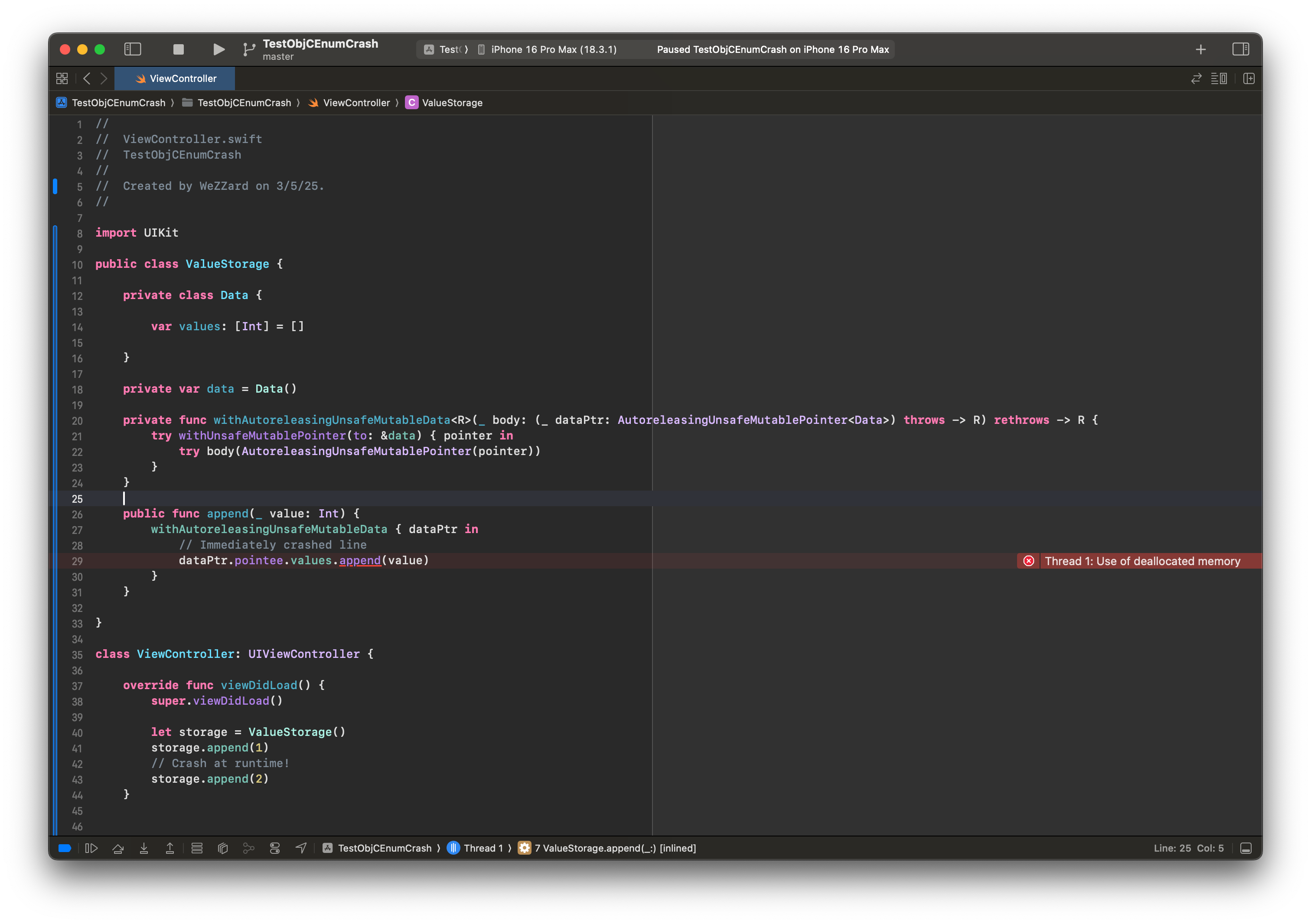
有趣的是,将 AutoreleasingUnsafeMutablePointer 替换为 UnsafeMutablePointer 可以解决这个问题。
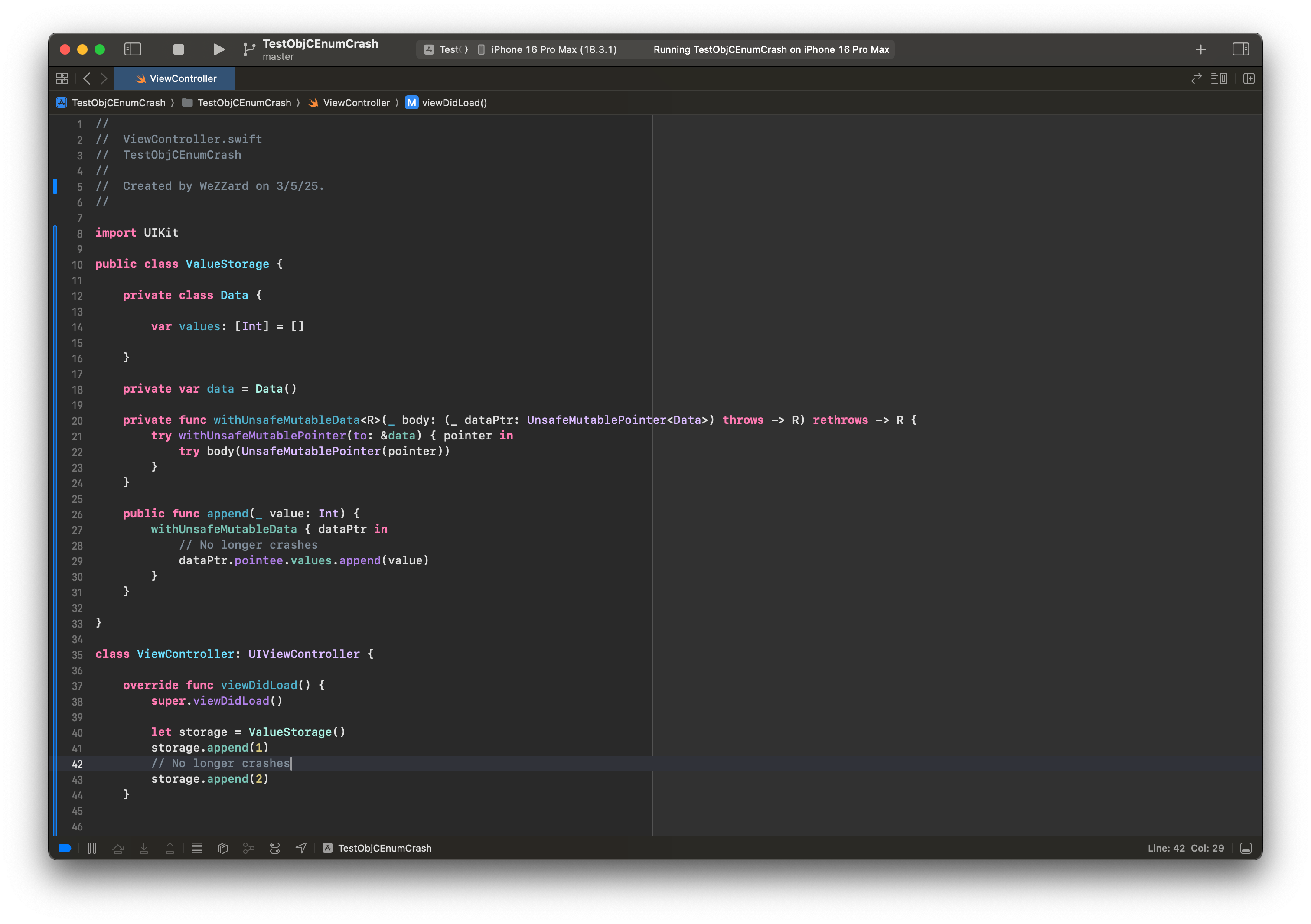
调查崩溃现场
反汇编有问题的程序后,我们可以发现 Array 的追加函数内联到了 ValueStorage.append 函数中。关键问题是程序在 Array 重新分配后没有重新获取 Array 的缓冲区对象。这导致使用寄存器 r12 计算的地址指向旧缓冲区(如果确实发生了重新分配)。这段反汇编代码可以被简化为:
asm
以下是 ValueStorage.append 的完整反汇编代码:
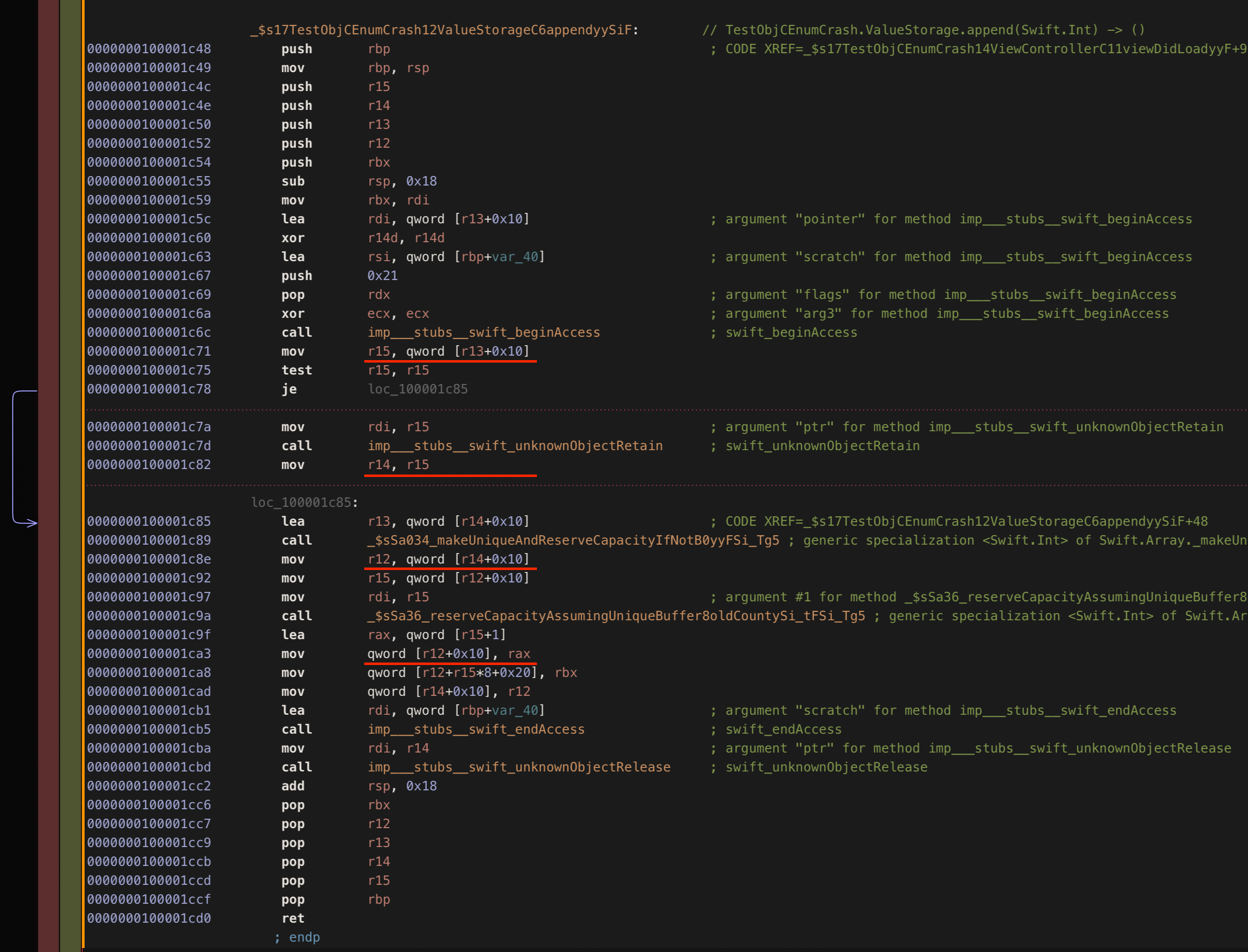
检查 Swift 标准库代码发现,其实际上是通过访问 self 上的 _buffer 属性来更新元素计数并插入新元素,而不是使用现有的旧缓冲区变量。Swift 编译器错误地删除了目标代码中重新获取 _buffer 对象的操作。
swift
为什么 Swift 编译器删除了代码?
通过检查中间编译产物,我们可以在"优化 SIL"输出中找到初始错误编译,这可以通过在调用 swiftc 时添加 -emit-sil 参数获得。比较使用 AutoreleasingUnsafeMutablePointer(左侧)和 UnsafeMutablePointer(右侧)程序的优化 SIL,我们发现使用 AutoreleasingUnsafeMutablePointer 时,数组存储的关键 load 指令缺失。
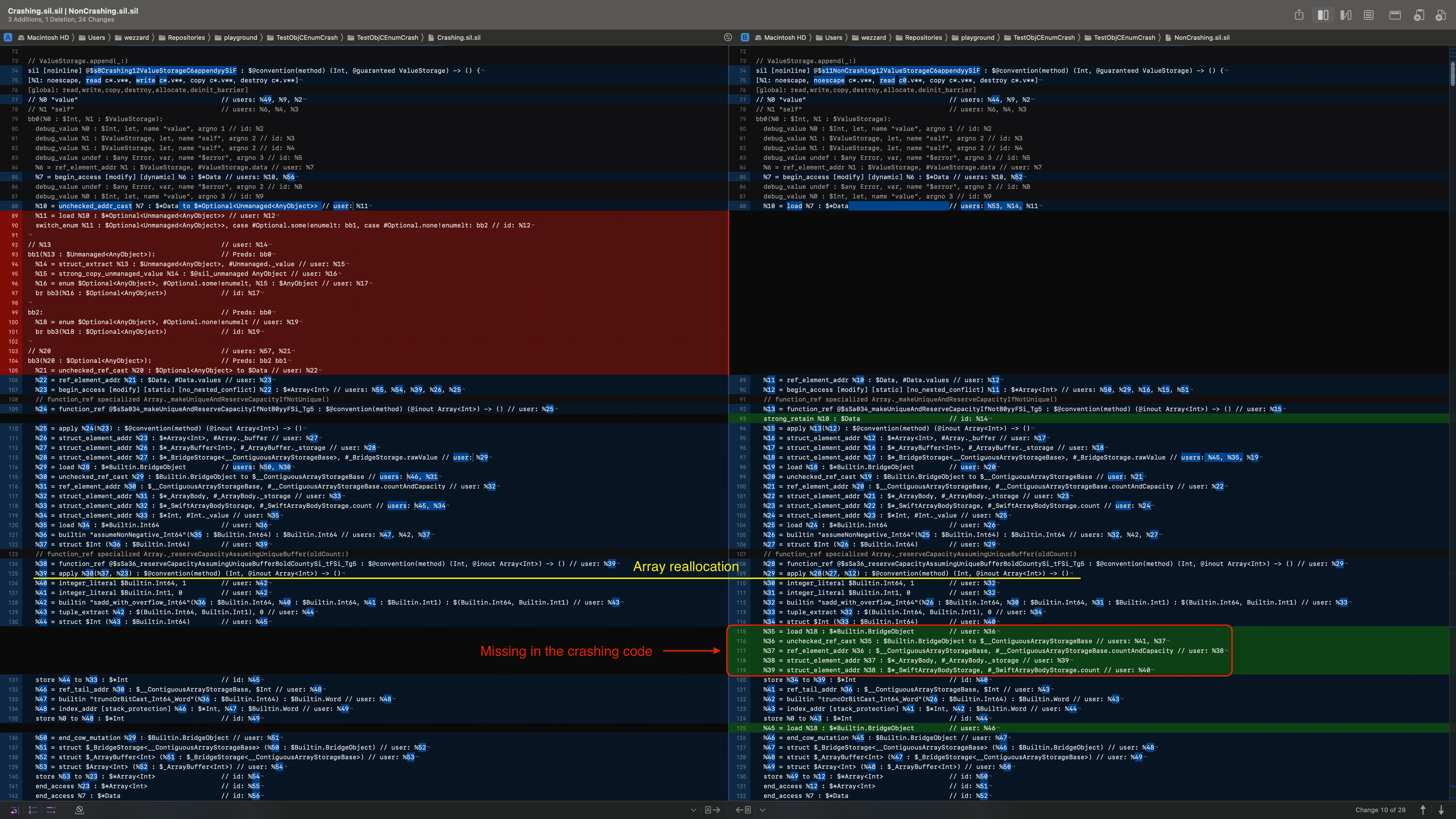
为了确定哪个编译器过程移除了这个 load 指令,我们可以使用 -Xllvm 参数启用编译器中的调试打印。具体来说,我们可以使用 --sil-print-function 让编译器在每次有修改时打印指定函数的 SIL:
shell
此分析的关键日志可总结为:
sil
从这些日志中,我们可以清楚地看到 redundant load elimination (冗余 load 指令消除,下称 RLE) 过程删除了以下 load 指令:
sil
思考修复方案
要完善修复方案,我们首先需要了解 RLE。这个优化过程通过消除虚拟寄存器和实际寄存器的冗余 "get 和 set" 操作来优化代码。考虑下面这个有关虚拟寄存器的例子:
sil
一个更优的等效版本会立即返回 %1,因为 %2 只是一个中间结果。这是 RLE 应该正确处理的情况。这里,我们称之为情况 1。
sil
然而,考虑这个更复杂的情况:
sil
在这里,消除 %3 = load %x 取决于 Foo 是否修改了 %x 的内容。如果修改了,我们就不能直接返回 %1,因为 %3 = load %x 加载了更新后的内容。这里,我们称之为情况 2。
现在我们可以开始看看 Swift 中 RLE 的有关实现了。其入口位于 RedundantLoadElimination.swift 文件:
swift
从这个入口点阅读代码,我们发现其算法与经典的 RLE 方法不同:
- 它在每个逆序的基本块中反向迭代所有指令,以查找所有
load指令 - 对于每个
load,它检查其先前的指令以查找:- 可用的
store指令进行优化(对应第一种情况) - 可用的
load指令进行优化(对应第二种情况),如果当两个load之间没有对地址有副作用的函数调用的话
- 指令扫描有复杂度预算限制
比较 RLE 与 AutoreleasingUnsafeMutablePointer 和 UnsafeMutablePointer
的详细行为,我们可以获得如下日志:
text
text
这揭示了:
- 使用
AutoreleasingUnsafeMutablePointer时,RLE 认为数组重新分配函数对load指令操作数的地址是"透明的",从而启用了 load 指令消除 - 使用
UnsafeMutablePointer时,RLE 正确地认识到该函数会覆写地址,从而阻止了 load 指令消除
对于情况 2 所属场景,Swift 6 算法检查 load 的所有先前指令,以确定 load 操作数的源和 load 指令本身之间的函数调用的副作用。
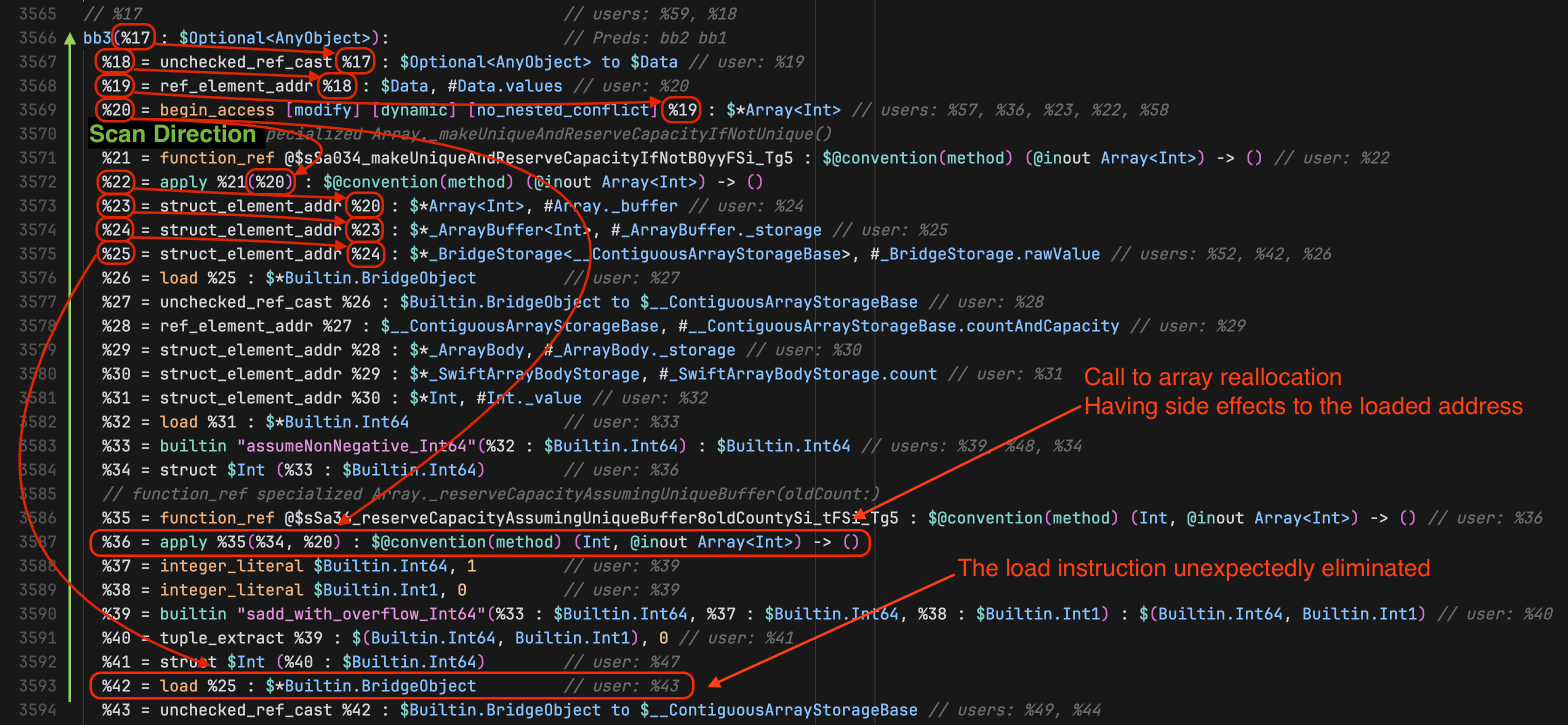
在这里,关键的发现是 Swift 编译器仅在 load 操作数的最终源头有未知逃逸结果时才会考虑函数的副作用。通过在 AliasAnalysis.swift 中的函数设置断点,我发现了两种指针类型之间的关键差异:
- 使用
AutoreleasingUnsafeMutablePointer时,编译器检查load指令的操作数的定义源是否逃逸。当确定不逃逸时,编译器将错误地假设函数没有副作用。(line 376) - 使用
UnsafeMutablePointer时,编译器将获取数组重新分配函数的全局副作用(可能来自@_effects属性。只有标记为readOnly或readNone的函数会被视为无副作用。)(line 381)
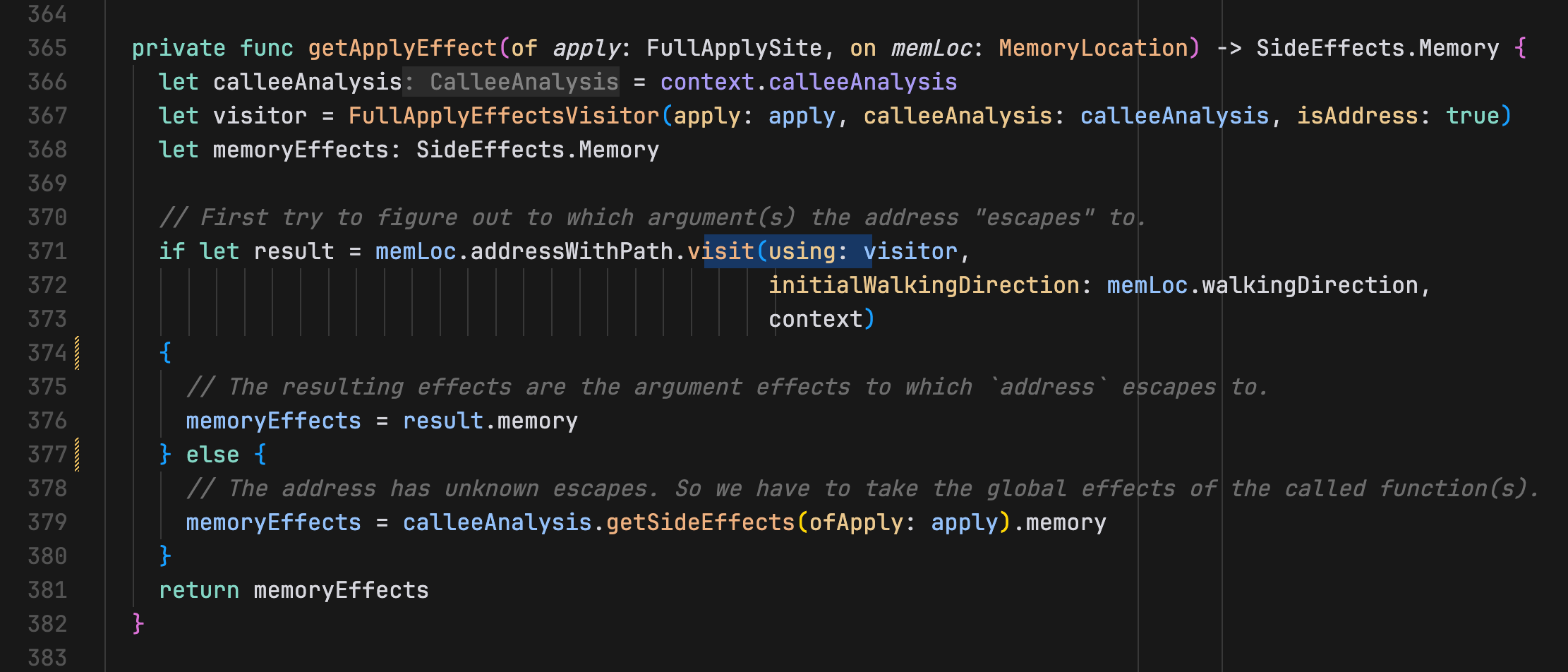
于是我们需要对第 371 行的 visit 函数进行进一步调查。该行会对 load 指令的操作数执行逃逸分析。下图说明了这个过程:

以下是逃逸分析的过程:
- 沿着 use-def chain (使用-定义链) 向上走,分析逃逸行为
- 每一步都将构建一个路径,表示如何从该点推导出
load指令的操作数
但当我们遇到 AutoreleasingUnsafeMutablePointer 的 pointee getter 实现时情况会变得复杂。它在上述逃逸分析过程中是一个非平凡的案例:
swift
实现细节揭示,AutoreleasingUnsafeMutablePointer 必须将引用从 Optional<Unmanaged<AnyObject>> 转换为 Pointee 类型以维持 +0 引用计数。这种转换通过 _unsafeReferenceCast 函数执行:
swift
编译器将其转换为 Builtin.castReference 函数,最终在 SIL 中表示为 unchecked_ref_cast 指令:
sil
因为 AutoreleasingUnsafeMutablePointer 的引入,使得 $SourceSILType 或 $DesintationSILType 可能是 Optional 类型,最终导致了问题:
sil
此指令可以在 Optional 和非 Optional 类型之间进行转换,有效地包装或解包值。由于逃逸分析沿着 use-def chain (使用-定义链) 走,路径必须严格反映如何从定义点推导出 load 操作数,这些隐式的 Optional 转换会创建的路径不匹配,如图所示:

通过检查 WalkUtils.swift 中的 walkUpDefault 函数我们可以确认这一假设:该函数在向上走期间处理各种指令类型,但缺乏对 unchecked_ref_cast 中 Optional 转换的适当处理:
swift
修复方案
解决方案是在 use-def chain (使用-定义链) 走向上游时考虑 Optional 和非 Optional 类型转换:
swift
下图说明了这个修复如何适应逃逸分析过程中的 Optional 和非 Optional 类型转换。当逃逸分析过程遇到 Optional 和非 Optional 类型之间的 unchecked_ref_cast 时,该修复通过调整路径以考虑枚举 case 差异,确保了正确的路径转换。

在 def-use chain (定义-使用链) 分析中,walkDownDefault 函数也需要类似的更改:
swift
实施此修复后,编译使用 AutoreleasingUnsafeMutablePointer 的代码产生的日志显示 RLE 正确识别潜在的副作用:
text
优化后的 SIL 现在保留了数组重新分配后的关键 load 指令:
sil
调试 Swift 编译器的技巧
获取 Swift 编译器的中间产物
要检查 Swift 编译器在每个编译阶段的中间表示:
shell
利用 LLVM 传递参数
LLVM 提供了许多可与 Swift 一起使用的传递参数:
shell
构建 Swift 编译器
需要注意的是,在这篇文章中,我们是在调试编译器的行为细节,但 Swift 编程语言和标准库捆绑在一起。由于问题与 Array.append 函数的内联相关,我们应该构建一个 debug 版本的编译器和一个 release 版本的标准库,以确保 Array.append 的内联成本尽可能低。你可以使用以下命令实现:
shell
SIL 和 LLVM IR 的语法高亮
你可以在 VS Code(或 Cursor)扩展市场中搜索"WeZZard"以获取相关 IDE 中的 SIL 语法高亮。
你可以在 VS Code(或 Cursor)扩展市场中找到 Ingvar Stepanyan 的"LLVM"扩展,以获取相关 IDE 中的 LLVM IR 语法高亮。